🏁 Your Number One NBA Drafting Agent, so YOU won't make mistakes
Every year the NBA holds thier draft where prospects from all over the world compete amongest themselves to get drafted into the NBA and have a shot of becoming an NBA Player. As daunting it is for the players to get drafted and work hard, it is also VERY hard to make the right pick for an NBA Team. There is always a stigma every year surronding draft busts and how these prospects end up turning into the players that they weren't envoisned to be. Our project aims to take out all the outside nosie and bais revolved around these players and make sure that teams, agents and people in the basketball world know HOW TO MAKE THE RIGHT PICK.
NBA 2k25 Draft Analyzer: You're Number One Draft Agent is an web application aimed to help you make the right pick for the 2025 NBA Draft. Based on metrics such as how well a player preforms, what specific league they are in and what team in looking for coming into the draft, this web application takes all that information and creates a draft board on how the draft should play out. Using Machine Learning and Sentiment Analysis on players and NBA Teams, this application is ready to take youre drafting skills to the next well. Built through Python and it various libraries such as pandas, sklearn, seaborn and frontend development with react.js.
Here is a Demo of our project here: Demo Reel
🥇 Key Features
Webscrapping
Through webscrapping we were able to get the data needed in order to make the right calls for where the player should land in the draft. By getting the players stats and how they preformed pre-draft and also getting previous draft results, we were able to use this information to help us create a machine learning model that can make an accruate prediction of the draft order and where each player should land
Sentiment Analysis
By using ESPN Articles and researching around the NBA Draft, we were able to quantify words and through sentiment analysis, we were able to understand what each team was looking for coming into the NBA Draft and how they would approach the draft. By using previous years as a training model, we were able to understand how to match up the words of what the team wanted and see hoe they actually drafted and through this, we were able to understand how each team would draft.

Machine Learning: Naive Bayes
When thinking of which specific model to use, we decided to use Naive Bayes as this is commonly used in recommendation systems and widely used for its efficiency and accuracy. The Selected Features that we used for each player was thier performance stats, player position, league. We then used the ML model to predict which “team need” category each player best fits in to as each team had a specific need coming into the draft. Through this, we matched players to teams based on their needs using the 2024 draft order.
Frontend: React.js
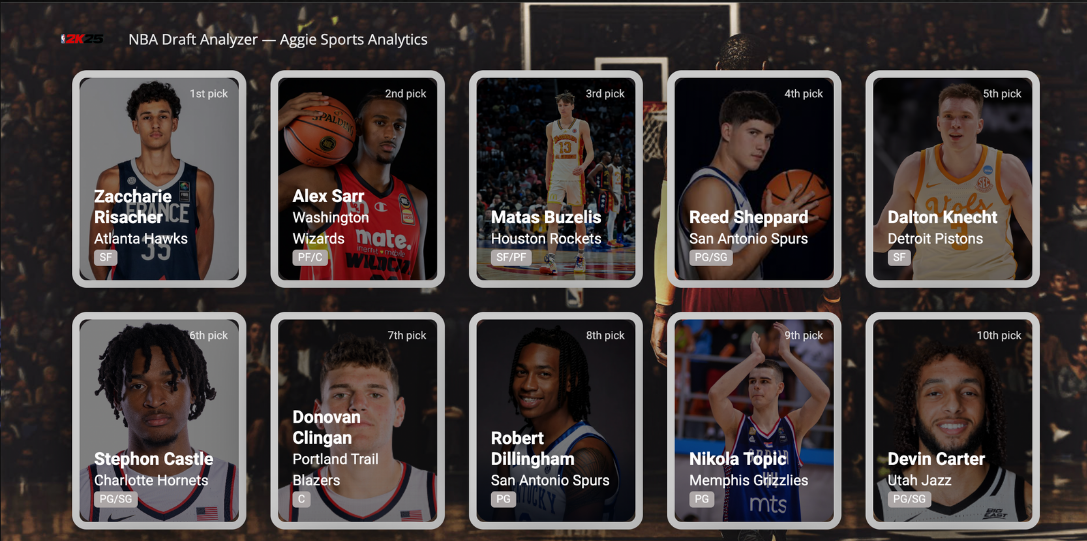
By using react.js and figma, we were able to come uop witha comprehensive user-friendly web application in where each player had thier own player card and through creating a hashmap, we were able to connect the backend csv file into the frontend with all of the players information an d hwere they would land in the draft. Using react.js allowed us to connect the frontend and backend seamlessly and be able to have full freedom in having a nice creative frontend that was engaing and useable.
📁 Code
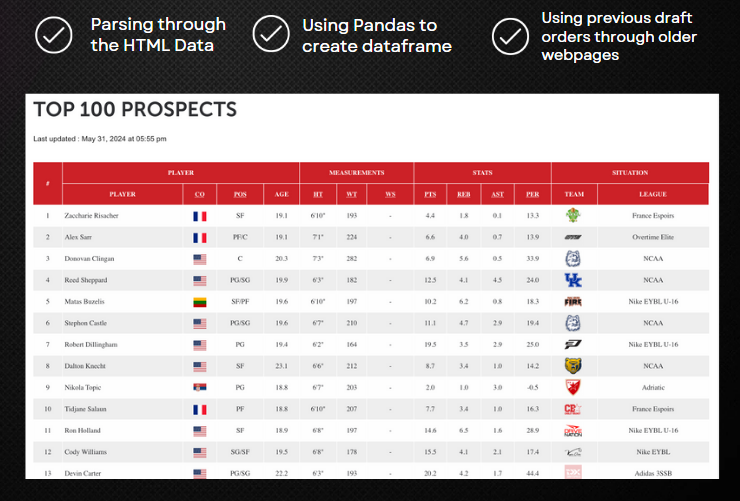
When obtaining the NBA draft data fort all of the prospects for this upcoming draft, we used the draft express wesbite and parsed through their table in where they had all the information about the players in the draft and thier stats
url = 'https://www.draftexpress.com/rankings/Top-100-Prospects/printable'
page = requests.get(url)
soup = BeautifulSoup(page.text, 'html')
table = soup.find_all('table')
world_table_titles = [title.text.strip() for title in world_titles ]
print(world_table_titles)
df = pd.DataFrame(columns = world_table_titles)
...After creating an Empty dataframe with all of the headers from the Table given to us that we parsed through, we have to go through each table row and update it with the information that pertains to each player. We did this for the top 100 prospects in the NBA draft for this year. We also did the same thing for the previous draft so we can have the previous draft rersults as well
df = df.drop(columns=['Stats', 'Situation'])
# Define the name of the new column
new_column_name = 'Player'
# Initialize the new column with NaN values
df.insert(1, new_column_name, 0)
df = df.drop(columns=['Players'])
for row in column_data:
row_data = row.find_all('td')
individual_row_data = [data.text.strip() for data in row_data ]
# print(individual_row_data)
length = len(df)
df.loc[length] = individual_row_data
...After getting the CSV data for both the NBA top 100 prospects and getting the sentiment analysis around what each team is looking for coming into the NBA draft, we ran a Naive Bayes Machine Learning model in where we were able to break down individually all of the different measurements and statisitcs for each player and basedd on these stats, we were able to group it to categorize what type of player the prospect is and then match this to what the team is looking for:
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import CategoricalNB
from sklearn.metrics import accuracy_score
prospects2024 = pd.read_csv('Top100FinalProspects.csv')
teams2024 = pd.read_csv('2024NBADraft (1).csv')
prospects2024['Rank'] = prospects2024.index + 1
draft_results = []
for idx, team_row in teams2024.iterrows():
team = team_row['Team']
pos_needed = team_row['Pos']
matching_players = prospects2024[prospects2024['Pos'].str.contains(pos_needed.split('/')[0])]
if not matching_players.empty:
best_player = matching_players.iloc[0]
draft_results.append({
'Team': team,
'Player': best_player['Player'],
})
prospects2024 = prospects2024.drop(best_player.name)
final_draft_results = pd.DataFrame(draft_results)
le_team = LabelEncoder()
teams2024['team_encoded'] = le_team.fit_transform(teams2024['Team'])
le_position = LabelEncoder()
all_positions = pd.concat([teams2024['Pos'], prospects2024['Pos']]).unique()
le_position.fit(all_positions)
teams2024['Pos_encoded'] = le_position.transform(teams2024['Pos'])
prospects2024['Pos_encoded'] = le_position.transform(prospects2024['Pos'])
X = teams2024[['Pos_encoded']]
y = teams2024['team_encoded']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = CategoricalNB()
model.fit(X_train, y_train)
# Making predictions on the test set
# y_pred = model.predict(X_test)
# accuracy = accuracy_score(y_test, y_pred)
# print(f'Accuracy: {accuracy * 100:.2f}%')
print(final_draft_results.head(60))
prospects2024['predicted_team_encoded'] = model.predict(prospects2024[['Pos_encoded']])
prospects2024['Predicted_Team'] = le_team.inverse_transform(prospects2024['predicted_team_encoded'])
final_results_with_predictions = prospects2024[['Player', 'Pos', 'Predicted_Team']]
...For our frontend, we created a hashmap in where we were able to convert the csv file with all of the prospects ito individual player cards for each player and make them visible on our web application
let pickCounter = 1;
const parseCSV = (data) => {
const lines = data.trim().split("\n");
const headers = lines[0].split(",").map((header) => header.trim());
return lines.slice(1).map((line) => {
const values = line.split(",").map((value) => value.trim());
let playerData = {};
headers.forEach((header, index) => {
playerData[header] = values[index];
});
return playerData;
});
};
const getPickNumber = (pickCounter) => {
if (pickCounter === 11 || pickCounter === 12 || pickCounter === 13) {
return `${pickCounter}th pick`;
}
const lastDigit = pickCounter % 10;
const suffix =
lastDigit === 1
? "st"
: lastDigit === 2
? "nd"
: lastDigit === 3
? "rd"
: "th";
return `${pickCounter}${suffix} pick`;
};
const createNewPlayer = (team, player, imageURL, position, stats) => {
const card = document.createElement("div");
card.classList.add("card");
card.innerHTML = `
<div class="card-inner">
<div class="card-front" style="background-image: url('${imageURL}');">
<h1>${player}</h1>
<div class="date">${getPickNumber(pickCounter)}</div>
<div class="tags">
<div class="tags">${team}</div>
</div>
<div class="tags">
<div class="tag">${position}</div>
</div>
</div>
<div class="card-back">
<h1>${player}</h1>
<div class="tags">
<h2>Stats:</h2>
</div>
<p>Points: ${stats.Pts}</p>
<p>Rebounds: ${stats.Reb}</p>
<p>Assists: ${stats.Ast}</p>
</div>
</div>
`;
document.getElementById("card-container").appendChild(card);
pickCounter++;
};
const playersArray = parseCSV(csvData);
playersArray.forEach((player, index) => {
createNewPlayer(
player.Team,
player.Player,
player.ImageURL,
player.Pos, // Adding position here
{
Pts: player.Pts,
Reb: player.Reb,
Ast: player.Ast,
PER: player.PER,
}
);
});Through this hashmap, we were able to connect the backend and frontend together to make sure that our web application has all the draft picks in the right order with thier stats, position, and where they would land (specifically to what team they would get drafted by) and a picture for each player
🖱️ Future areas of improvement
- We want to account for last minute draft changes, such as wether or not someone drops out of the draft or if a team makes a trade. In a future update for this application we would want to have live updates and then make changes asynchronously in the background so it shows our users the right NBA Draft predicition
- We also want to make a additional feature in which when you click on each player card, it will show the news and "Buzz" around a specific player. Through using twitter sentiment analysis and extracting tweets on each player, this would enable users toi get insight about each specific player and get more of an understanding on what people think about a specific player
- An additional feature that we want in an upcoming update would be for users to add thier own custom player to see based on our model for a specific year, where they would land in the draft. Creating custom drafts based on whatever the user inputs.
🖥️ Technology
⭐ Python
⭐ React.js
⭐ Pandas
⭐ BeautifulSoup
⭐ Seaborn
⭐ Naive Bayes Machine Learning Model
⭐ Sklearn
🌐 THE TEAM
