🏁 AI-powered Chatbot for draft and trade guidance in Fantasy Football and Basketball
Every year, over 60 million Americans play fantasy sports. Many players depend on online tools for trade and draft guidance. These trade analyzers are purely data driven and poorly designed. Our project aims to revolutionize fantasy sport trade analyzers.
HIKE is a chatbot for amazing personalized advice in Fantasy Football and Basketball. It provides conversational advice using a combination of time series analysis, score projections, and LLM-powered sentiment analysis. The project is built entirely in Python using the LangChain, Statsmodels, and Streamlit libraries.
Watch the demo video here!
🔑 Key Features
Large Language Model (LLM) Integration
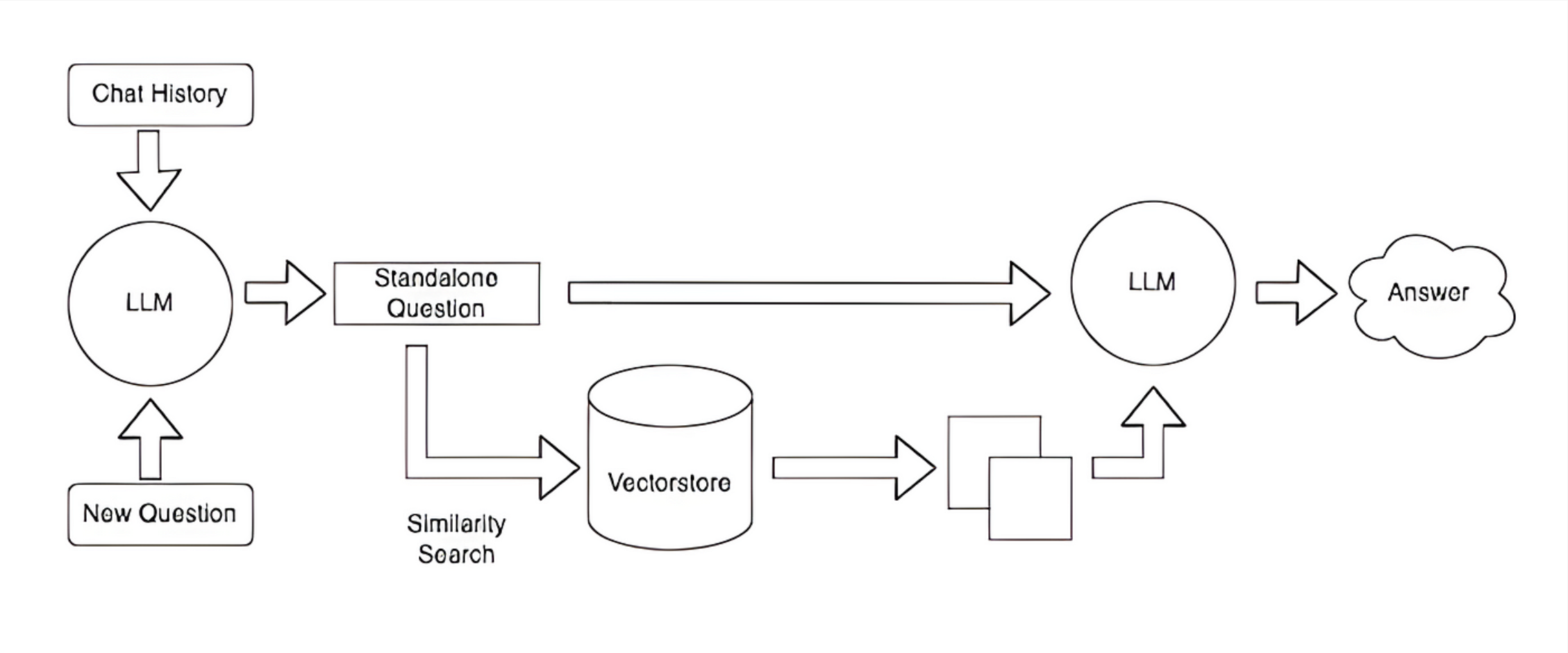
HIKE utilizes LLMs through Retrieval Augmented Generation (RAG) for natural language chatting and conducting sentiment analysis on sports news and injury data.
Time Series Analysis
HIKE implements time series analysis to analyze data over the sports season. This allows HIKE algorithm to understand data at specific times during the football and basketball seasons.
Streamlit Frontend
The frontend is built using Streamlit, allowing for easy modification and rapid performance. This choice eliminates the need for conventional request-response cycles between a frontend and backend, significantly reducing latency.
💻 Code
To obtain Football data, we use a maintained open-source Kaggle dataset with robust data covering the past five seasons, including the most recent reason in 2023.
This dataset is quite detailed and needs some processing to only contain relevant information for our algorithm.
for week in range(1, num_weeks + 1):
file_name = f'week{week}.json'
week_data = read_json_file(file_name)
week_data_filter = week_data["data"]
for player in week_data_filter:
name = player.get('PLAYER NAME', '')
team = player.get('PLAYER TEAM', '')
position = player.get('PLAYER POSITION', '')
proj = player.get('PROJ', 0)
total = player.get('TOTAL', 0)
try:
proj = float(proj) if proj else 0
total = float(total) if total else 0
except ValueError:
proj = 0
total = 0
ts_proj.loc[week, name] = proj
ts_total.loc[week, name] = total
...To source Basketball data, we use webscraping on the NBA website and the pandas library to filter data to the project needs.
for y in years:
for s in season_type:
api_url = 'https://stats.nba.com/stats/leagueLeaders?LeagueID=00&PerMode=PerGame&Scope=S&Season='+y+'&SeasonType='+s+'&StatCategory=PTS'
r = requests.get(url=api_url, headers=headers).json()
stats_df1 = pd.DataFrame(r['resultSet']['rowSet'], columns=table_headers)
stats_df2 = pd.DataFrame({'Year':[y for i in range(len(temp_df1))],
'Season_type':[s for i in range(len(temp_df1))]})
stats_df3 = pd.concat([stats_df2, stats_df1], axis=1)
df = pd.concat([df, stats_df3], axis=0)
print(f'Finish scraping data for the {y} {s}.')
lag = np.random.uniform(low=5,high=40)
print(f'...waiting {round(lag,1)} seconds')
time.sleep(lag)The Statsmodels library is implemented to run time-series analysis on data throughout the season.
ts_proj.index = pd.date_range(start='2024-01-01', periods=len(ts_proj), freq='W')
ts_total.index = ts_proj.index
final_data = []
for name, data in player_data.items():
proj_arima = ARIMA(ts_proj[name], order=(1, 0, 1), enforce_invertibility=True, enforce_stationarity=True).fit()
total_arima = ARIMA(ts_total[name], order=(1, 0, 1), enforce_invertibility=True, enforce_stationarity=True).fit()
...Then, we use LangChain to send our processed data to the LLM. The LLM analyzes these vast amounts of data to create calculated responses in natural language dialogue.
json_path = 'final_data.json'
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
loader = JSONLoader(file_path=json_path, jq_schema='.[]', text_content=False)
data = loader.load()
injury_loader = CSVLoader(file_path='injuryreports.csv', encoding="utf-8")
injury_reports = injury_loader.load()
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
vectors = FAISS.from_documents(data, embeddings)
injury_vectors = FAISS.from_documents(injury_reports, embeddings)
chain = ConversationalRetrievalChain.from_llm(
llm=ChatOpenAI(temperature=0.0, model_name='gpt-3.5-turbo', openai_api_key=OPENAI_API_KEY),
retriever=vectors.as_retriever())
injury_chain = ConversationalRetrievalChain.from_llm(
llm=ChatOpenAI(temperature=0.0, model_name='gpt-3.5-turbo', openai_api_key=OPENAI_API_KEY),
retriever=injury_vectors.as_retriever())
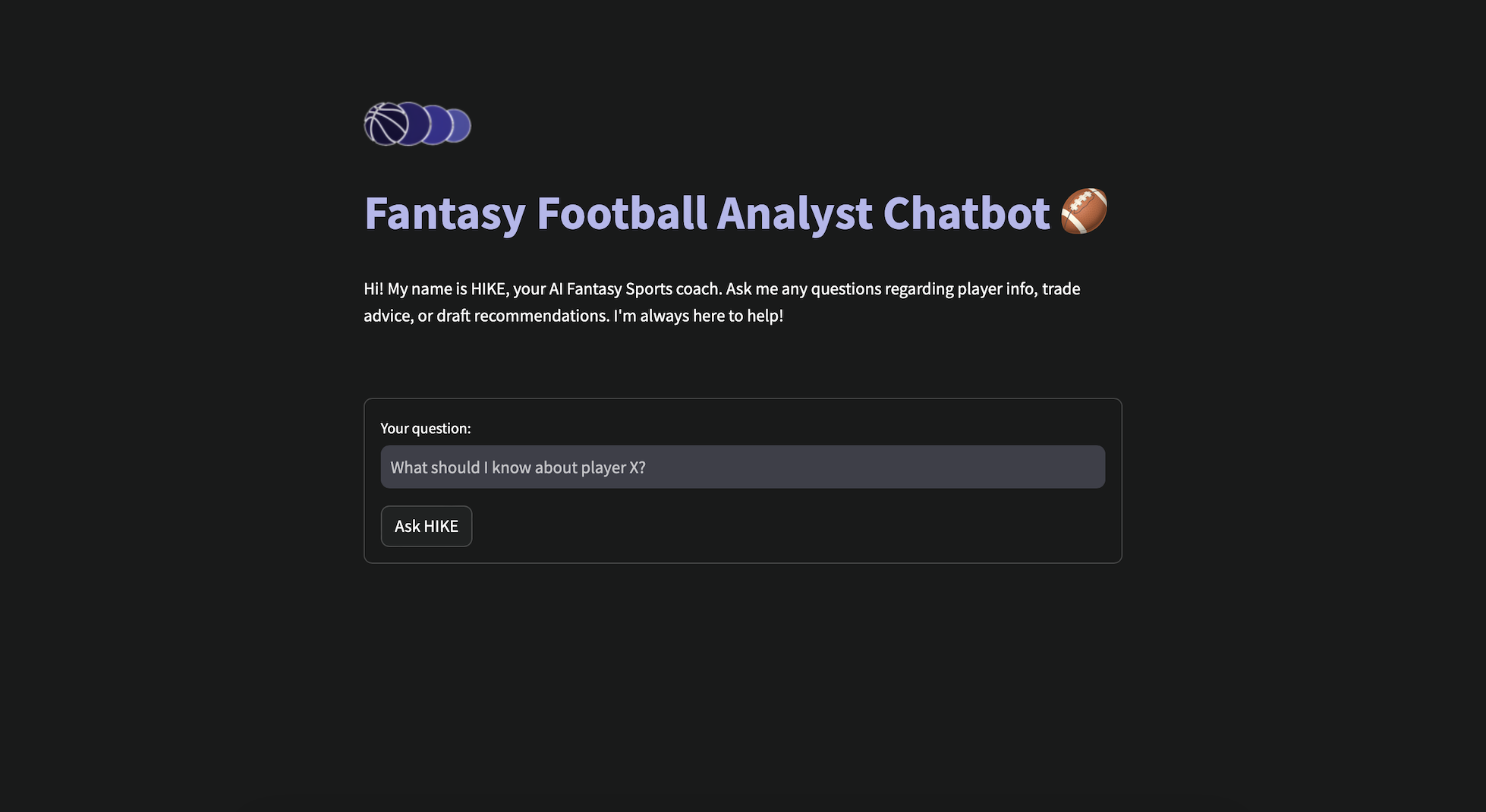
...Finally, we use Streamlit to package HIKE into an intuitive and beautiful chatbot interface.
st.set_page_config(page_title="HIKE", page_icon="asa.png", initial_sidebar_state="auto", menu_items=None)
st.image(logo_image, width=100, use_column_width=False)
st.title(f"Fantasy Football Analyst Chatbot 🏈")
st.markdown(
"""
<style>
h1 {
color: #B4B7ED !important;
}
.reportview-container {
margin-top: -2em;
}
#MainMenu {visibility: hidden;}
.stDeployButton {display:none;}
footer {visibility: hidden;}
#stDecoration {display:none;}
</style>
""",
unsafe_allow_html=True
)
...🪴 Areas of Improvement
- Data: The project could always have higher accuracy in trade and draft advice with better data procedures. This could be improved through better datasets and optimizing the data analysis process.
- Fine-tuning: Currently, HIKE uses a standard, 1.8 trillion parameter LLM. We could fine-tune a large language model for Fantasy Sport purposes to create a more powerful chatbot.
- Speed: Depending on the input, HIKE can take a few seconds to provide an output. With optimizastion, this delay could certainly be reduced to create a lower latency chatbot.
🚀 Further Uses
- The project can be implemented to support all sports, including baseball, soccer, hockey, cricket, and more.
- HIKE can be monitized into a SaaS product with more refinement on the core project
💻 Technology
- LangChain
- GPT-4
- Statsmodels
- Pandas
- Streamlit
🏆 Recognition
- First Place in the 2024 Winter Quarter ASA Case Competition.
{kind=link}